Inworld Voice 2.0: Improving TTS voice capabilities for increased realism in AI agents


Inworld Voice 2.0 capabilities
Over the last few months, we’ve been working on making significant improvements to Inworld’s voice offering. These voices offer emotional depth and realism through improved latency, rhythm, intonation, pitch variation, and natural pausing for more authentic experiences. These voices are now available in a standalone text to speech API or for use within Inworld Engine to power real-time characters and experiences.
- High-quality speech synthesis: Inworld utilizes advanced machine learning models to produce natural and expressive speech, ensuring an exceptional user experience.
- Speech synthesis customization: Customization options allow you to select different voices, and change the settings of the returned audio.
- Easy integration: Seamlessly integrate our TTS API with your application using our easy-to-use REST or gRPC APIs - using either basic or JWT authentication - all backed by comprehensive documentation. Alternatively, access voices from Inworld Studio to power characters for real-time experiences.
- Scalability and reliability: Designed to handle high volumes of requests, the API is built with scalability and reliability in mind to ensure uninterrupted speech synthesis.
- Developer-friendly tools: Access tools and resources, including a user-friendly developer portal, to simplify the integration process and manage your account.
The Mercenary
Mindfulness Coach
Educational
Fiery Sorceress
Available as a TTS API or integrated with Inworld Engine
The text to speech API allows access to Inworld voices at both design-time and run-time, making it accessible to developers who want to use voices as a standalone service.
curl --request POST \
1--header "Authorization: Basic INWORLD_API_KEY" \
2--data '{
3 "input": {
4 "text": "Hello world"
5 },
6 "voice": {
7 "name": "Timothy"
8 }
9}' \
10https://api.inworld.ai/tts/v1alpha/text:synthesize-syncSeamlessly integrate our TTS API with your application using our easy-to-use REST or gRPC APIs - using either basic or JWT authentication - all backed by comprehensive documentation. Alternatively, access voices from Inworld Studio to power characters for real-time experiences.
For current Inworld users who are using our AI platform to power characters and experiences, these 48 new Studio voices offer a variety of TTS options for different character types. We don't charge separately for our voice pipeline — it is included with the Inworld platform at no extra cost. For pricing information on custom cloned voices, please reach out to us.
Reduced latency for real-time conversations
We've made significant advancements in reducing latency for both our Inworld Studio and cloned voices, giving you more options to generate natural-sounding conversations. Our new voices have a 250ms end-to-end 50pct latency for approximately 6 seconds of audio generation. To achieve the perfect balance between latency, quality, and throughput, we applied the following approaches:
- Hyperparameter tuning enabled us to optimize quality and latency by implementing automatic quality evaluations and searching for inference hyperparameters. This iterative evaluation process is a fundamental part of machine learning to find the best values for variables in a model. This was a key part of achieving optimal model performance in our machine learning approach.
- Streaming generation allowed us to improve the real-time factor by producing audio in smaller segments. One segment is spoken while the next is generated, resulting in uninterrupted and continuous speech.
Training our Inworld Voice 2.0 model
The improvements that we've made to our voices are the result of a number of factors:
- New architecture: By implementing a lightweight diffusion-based TTS architecture, we were able to achieve more refined voice generation. Carefully curating the data used to train this model allowed us to strike a balance between quality and latency.
- Data cleaning: The data we used to train these voices came from Creative Commons licensed datasets, specifically LibriTTS-R, SLR83, and Hifi-TTS. We used approximately 20 hours of additional licensed audio, recorded specifically for our platform by professional voice actors, to enhance the pitch, pace, and emotional range of our model. To ensure reliable audio quality and transcription accuracy, we implemented a thorough cleaning pipeline that identifies and removes flawed samples, addressing issues like missing words and unintended punctuation. We also trained a set of ML classifiers to help us to automatically identify low-quality, noisy, and game-inappropriate recordings. We further enhanced our data cleaning process by manually listening to the audio to identify and remove imperfections like background noise and samples that sounded slow, monotone, or robotic.
- Model distillation: We used a much larger TTS model to augment the expressiveness of our voices. We generated audio with patterns not found in the training data, emphasizing text that results in expressive, dialogue-like speech. Using some of the same methods for data cleaning, we carefully filtered generations to ensure that only high-quality augmented samples were added.
Our methodology for benchmarking high quality voices
Selecting the right prompt is a crucial part of high-quality voice generation. The quality of a generated voice is greatly influenced by the nature of the prompt -- whether it’s dull or exciting. To ensure optimal voice generation, we employed a custom set of evaluation criteria to select the most suitable prompts and measure the quality of our model.
The standard method for evaluating TTS model output is through Mean-Opinion Score (MOS), where voice generations are rated on a scale of 1 to 5 by crowdsourced individuals. However, this approach is slow, expensive, and impractical for frequent model and data modifications during development.
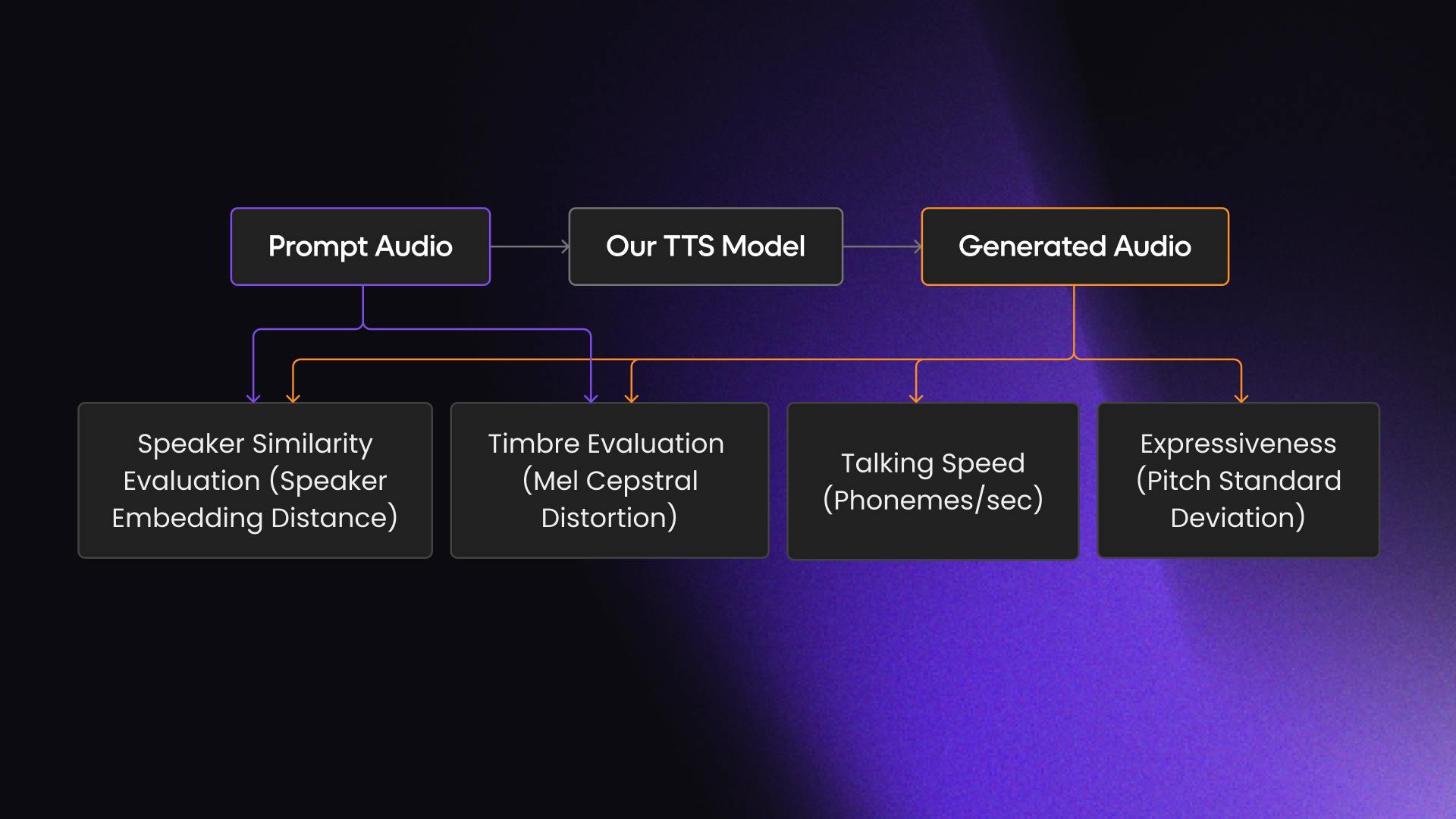
Instead, we developed an automated evaluation framework to assess prompt and generated voice quality across five categories: text generation accuracy, speaker similarity, prosody evaluation, talking speed, and expressiveness.
- Text generation accuracy: We verified the accuracy of our model's generated text by comparing it to the requested text using an Automatic Speech Recognition (ASR) model.
- Speaker similarity evaluation: To measure voice similarity between the generation and prompt, we employed a speaker verification model. This pretrained model converts the audio from the generation and prompt into dense embedding representations, allowing us to calculate the cosine similarity between the embeddings. The closer the embeddings are, the greater the similarity between the voices.
- Timbre evaluation: The Mel Cepstral Distortion (MCD) metric helped us quantify the spectral similarity between synthesized speech and a reference sample. It calculates the average Euclidean distance between their Mel-frequency cepstral coefficients (MFCCs). The MFCC representation characterizes the timbre of speech, the quality that makes voices sound different even when at the same pitch. A lower MCD value indicates a closer match between the synthesized and reference samples.
- Talking speed: Measuring phonemes per second is a reliable indicator of speech naturalness and helps avoid excessively slow or robotic voices. Striking a balance in the range of phonemes per second ensured our voices maintained an optimal tempo and pace while sounding natural.
- Expressiveness: We used Pitch Estimating Neural Networks (PENN) to measure pitch in the generated audio and assess expressiveness by analyzing the standard deviation of pitch. Our goal was to optimize for natural levels of pitch variation that align with voice expressiveness, avoiding monotone voices.
What's next
As part of our ongoing development, we will be adding voice cloning capabilities and multilingual support to Inworld Voices. We are also focused on adding contextual awareness to our voices, striving for more emotionally connected interactions. Stay tuned for upcoming announcements as we continue to develop our voice technology.